
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 포트포워딩 안될때
- 도커
- wan
- Decapsulation
- ubuntu
- 도커권한설정
- instancenotfoundexception
- 브로드캐스트
- 네트워크모델
- 우분투
- 페이로드
- 배열복사
- SpringApplication
- jmx
- name=springapplication
- 배열빈도수
- 백준1946
- javax.management.instancenotfoundexception: org.springframework.boot:type=admin
- 포트포워딩
- 모래시계출력
- dbeaver
- 리눅스환경
- 백준
- 디비버
- 유니캐스트
- springboot
- 리눅스계열
- 오름차순
- docker
- 배열최소값최대값
- Today
- Total
다잘하고싶어
자바 컬렉션 본문
Collection FrameWork
정적 자료 구조
동적 자료구조
컬렉션 프레임워크의 핵심 인터페이스
List
구현클래스
ArrayList<?>
LinkedList<?>
특징
주요메소드
리스트의 구현체 3개의 속도 비교
LinkedList
Set 집합
특징
구현클래스
주요 메소드
Queue
특징
메소드
Stack
특징
메소드
정렬
Collections의 sort() 를 이용한 정렬
사용자 정의 comparable 만들기
comparable
Hash를 사용하는 이유?
정렬의 종류
Comparable interface
Comparator
Collection Framework
⇒ 자료구조 관련된 인터페이스, 클래스
- 객체들을 한 곳에 모아두고 편리하게 사용할 수 있는 환경을 제공
정적 자료 구조( Static data structure)
- 고정된 크기의 자료구조
- 대표적 예시 : 배열
- 선언 시 크기를 명시하면 바꿀 수 없음
동적 자료 구조( Dynamic data structure)
- 요소의 개수에 따라 자료구조의 크기가 동적으로 증가하거나 감소
- 대표적 예시 : 리스트, 스택, 큐..
⇒ 자료구조의 종류는 결국 어떤 구조에서 얼마나 빨리 원하는 데이터를 찾을 수 있는가 (추가, 삭제, 수정) 에 따라 결정된다.
- 순서를 유지할 것인가?
- 중복을 허용할 것인가?
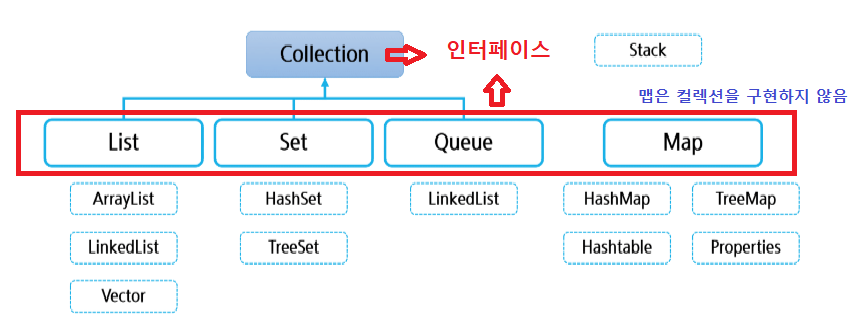
컬렉션 프레임워크의 핵심 인터페이스
- List
- Set
- Map
- Queue
List
구현클래스
- ArrayList
- LinkedList
- Vector
ArrayList<?>
= Array + List
Q. 어느정도의 크기가 차서 자리가 더 필요하다면?
→ 더 큰 배열을 새롭게 만들어서 값을 복사해서 넣는다.
→ 사용할때는 동적으로 만들어지는 것처럼 보이지만, 실제로는 배열의 기본적인 특징을 가지고 간다.
Q. 중간에 값을 넣거나, 삭제한다면?
→ 이미 들어가있는 값들을 앞/뒤로 미는 과정이 필요하다.
→ 시간이 오래걸린다.
Q. 조회는 왜 빠를까?
→ 배열이니까 인덱스 접근이 가능하기 때문
LinkedList<?>
= 연결리스트
구현방법1 ⇒ 단순 연결 리스트 Singly Linked List
구현방법2 ⇒ 이중 연결 리스트 Doubly Linked List

Q. 삽입과 삭제가 빠른 이유?
그냥 중간에 넣어서 연결해주면 되기 때문이다.
Q. 조회가 느린이유?
노드를 하나하나 거쳐서 확인해야한다.
특징
- List 는 내부적으로 배열을 이용하여 데이터를 관리( ArrayList, Vector 만! LinkedList는 제외)
- 순서가 있는 자료구조
- 중복을 허용
주요메소드
- isEmpty()
- remove( 인덱스 )
- remove( 값) → 중복된 값 존재 시 앞의 것만 삭제
- clear() → 전체 값 삭제
- add( 값 )
- get( 값 )
- add(인덱스, “값”) → 지정한 인덱스에 값 넣기
- 반복문 활용한 조회
Iterator<String> e = names.iterator();
while(e.hasNext()) {
System.out.println(e.next()); //.next() -> 다음원소를 꺼낸다.
}package test01;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Test01 {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("안중근");
names.add("이봉창");
names.add("유관순");
names.add(0,"이순신");
names.add(3,"안중근");
System.out.println(names);
//비었는지 체크 => isEmpty();
System.out.println(names.isEmpty());
//원소의 개수
System.out.println(names.size());
//수정
names.set(2, "세종대왕");
System.out.println(names);
//조회1
for (String name : names) {
System.out.println(name);
}
//조회2 -> 반복자사용
Iterator<String> e = names.iterator();
while(e.hasNext()) {
System.out.println(e.next()); //.next() -> 다음원소를 꺼낸다.
}
//인덱스를 사용한 삭제
names.remove(2);
System.out.println(names);
//값 삭제
names.remove("이순신");
}
}
Q. for 문을 돌면서 중복된 값을 모두 삭제하고자 할 때 아래 코드의 문제점?

39번 라인에서 remove 하면 List 는 동적자료형이므로 전체 크기가 줄어든다.
따라서 모든 원소를 확인하기 위해서는 뒤에서부터 체크해서 전체크기가 줄어들더라도
모든 값을 체크하는데 문제가 생기지 않도록 만들어야 한다.
해결한 코드

리스트의 구현체 3개의 속도 비교
ArrayList, LinkedList, Vector
package test02;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Vector;
public class Test02 {
public static void main(String[] args) {
List<Object> al = new ArrayList<Object>();
List<Object> ll = new LinkedList<Object>();
List<Object> v = new Vector<Object>();
test1("순차적 추가 - ArrayList -", al);
test1("순차적 추가 - LinkedList -", ll);
test1("순차적 추가 - Vector -", v);
test2("중간에 추가 - ArrayList -", al);
test2("중간에 추가 - LinkedList -", ll);
test2("중간에 추가 - Vector -", v);
test3("데이터 조회 - ArrayList -", al);
test3("데이터 조회 - LinkedList -", ll);
test3("데이터 조회 - Vector -", v);
}
public static void test1(String testname, List<Object> list) {
long start = System.nanoTime(); //시작시간
for (int i = 0; i < 50000; i++) {
list.add(new String("Hello")); //맨 뒤에 추가
}
long end = System.nanoTime(); //끝 시간
System.out.printf("%s \\t 소요시간 : %15d ns. \\n", testname, end-start);
}
public static void test2(String testname, List<Object> list) {
long start = System.nanoTime(); //시작시간
for (int i = 0; i < 50000; i++) {
list.add(0, new String("Hello")); //맨 앞에 추가, (= 중간에 추가)
}
long end = System.nanoTime(); //끝 시간
System.out.printf("%s \\t 소요시간 : %15d ns. \\n", testname, end-start);
}
public static void test3(String testname, List<Object> list) {
long start = System.nanoTime(); //시작시간
for (int i = 0; i < 50000; i++) {
list.get(i);
}
long end = System.nanoTime(); //끝 시간
System.out.printf("%s \\t 소요시간 : %15d ns. \\n", testname, end-start);
}
}

- 중간에 추가하는 경우 ArrayList 와 Vector 가 유난히 느린 이유는?
- 배열을 가지고 구현했으므로, 특정 위치에 넣기 위해서 나머지 값들을 이동시켜야 하기 때문
- LinkedList 는 참조값으로 연결되어있으므로 중간에 값을 추가하는 것이 빠르다.
⇒ 값을 추가하는 경우 LinkedList 가 빠르고, 조회하는 경우에는 ArrayList 가 빠르다.
LinkedList
- 제일 처음 Node의 주소값을 가지고 있다. Node 들은 다음 요소의 참조값과 데이터로 구성됨
Set _ 집합
특징
순서가 없다
중복을 허용하지 않는다
구현클래스
- HashSet → 해쉬코드를 이용해 값을 저장하는 방법
- TreeSet → (red - black) tree 를 이용해 값을 저장하는 방법
주요 메서드
- add(값)
Q. Hashset 과 TreeSet은 완전히 동일하게 동작할까?
- Hashset
→ HashSet 은 해시테이블에 원소를 저장
→ 성능면에서 우수하다고 알려져 있으나, 원소들의 순서가 일정하지 않음
- TreeSet
→ TreeSet 은 red-black tree 에 원소 저장
→ 값에 따라 순서가 결정( ex. 가나다 순)
→ 값을 순서대로 정렬할 필요가 있다면 고려해볼만한 선택지
Q. HashSet 중복 허용 안함 이해하기
package test02;
public class Person {
private String name;
private String id;
public Person(String name, String id) {
this.name = name;
this.id = id;
}
@Override
public String toString() {
return "Person [name=" + name + ", id=" + id + "]";
}
}
public class Test02 {
public static void main(String[] args) {
Set<Person> set = new HashSet<>();
Person p1 = new Person("김김김","880126");
Person p2 = new Person("박박박","880126");
set.add(p1);
set.add(p2);
System.out.println(set);
}
}

두 개 다 들어가 있음, 왜? 해쉬코드 값과 equals 메소드 둘 다 다르다고 나옴
→ HashSet 은 해쉬코드와 equals 두 개 가 같아야 같은 걸로 본다.
따라서 오버라이드 해야한다. Person 클래스에 아래의 코드 추가.
@Override
public int hashCode() {
return this.id.hashCode();
}
@Override
public boolean equals(Object obj) {
if(obj instanceof Person) {
Person other = (Person) obj;
return this.id.equals(other.id);
}else {
return false;
}
}
⇒ 코드 분석
if(obj instanceof Person) {
⇒ 만약 파라미터의 obj 가 Person의 성질을 가지고 있다면(= obj가 Person 으로 만든 객체라면)
Person other = (Person) obj;
⇒ 그 obj 를 Person other 에 넣고 ( 이제 너 Person 으로 봐줄게)
return this.id.equals([other.id](<other.id>));
⇒ Person의 id 값과 other의 id값이 같은지를 체크
⇒ 원래 equals 는 주소비교연산자인데, 값이 같으면 같다고 재정의
@Override public int hashCode() { return this.id.hashCode(); }
⇒ 원래 .hashcode() 는 문자열을 가지고 어떤 로직을 돌려서 고유한 정수값을 나타내는 것.
그런데 Object.hashcode() 를 들어가보면 hashCode() 가 따로 정의되어있지 않다.
따라서 같은 id 값을 가지고 있다면 같은 해시코드를 return 하도록 재정의한 것.
package test02_Set;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Test01 {
public static void main(String[] args) {
//Set 집합을 나타내는 자료구조
//중복 허용안함
//순서 없음
Set<String> set = new HashSet<>();
set.add("홍길동");
set.add("홍길동");
set.add("랄랄라");
set.add("마마마");
System.out.println(set);
System.out.println("홍길동".hashCode()); //문자값을 고유한 정수값으로 나타낸 것.
System.out.println("홍".hashCode()); //문자값을 고유한 정수값으로 나타낸 것.
System.out.println(new String("홍길동").hashCode()); //문자값을 고유한 정수값으로 나타낸 것.
//왜 객체로 만든 홍길동과 문자열로 생성한 홍길동이 같은 해시코드값이 나올까? 해시코드 안에서 재정의 해두었기때문에
//같은 문자열이면 같은 해시코드 값이 나온다.
System.out.println("홍길동".equals("홍길동"));
//반복자
Iterator<String> e = set.iterator();
while(e.hasNext()) {
System.out.println(e.next());
}
}
}

Map
특징
Key 와 Value 를 하나의 Entry 로 묶어서 데이터 관리함
순서가 없음
Key 에 대한 중복은 허용되지 않음
Value 는 중복가능
사전과 같은 자료구조
각각의 값은 키로 구별

⇒ HashMap 은 중복된 새로운 값을 넣을 경우, 새로운 값으로 대체된다.

⇒ TreeMap 은 키값의 알파벳 순으로 정렬된다
없는 값으로 키를 가져온다면? null 뜬다.
주요 메서드
- get(키) → 키로 값 가져오기
- containsKey(키) → 키가 있는지 확인
- containsValue(값) → 값이 있는지 확인
- put( 키, 값) → 값 넣기
- entrySet() → 맵의 키와 밸류값 가져오기
//맵을 반복문 돌리기
for(Map.Entry<String, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + entry.getValue());
}
반복문 사용하기 1
Iterator<String> e = map.keySet().iterator();
while(e.hasNext()) {
String key = e.next();
System.out.printf("키 : %s, 값 : %s \\n",key, map.get(key));
}
반복문 사용하기 2
for (String key : map.keySet()) {
System.out.printf("키 : %s, 값 : %s \\n",key, map.get(key));
}
Queue
특징
- Queue 는 인터페이스, 구현체는 LinkedList 를 사용
- FIFO
메소드
- peek() → 가장 앞에 있는 것을 조회
- poll() → 값 빼기
- offer() → 값 넣기
Stack
특징
- Stack 클래스를 사용
- LIFO
메소드
- peek() → 가장 앞에 있는 것을 조회
- pop() → 값을 빼기
- push → 값 넣기
정렬
- 순서를 가지는 Collection들만 정렬 가능
- List 계열
- Set 에서는 SortedSet 의 자식객체
- Map 에서는 SortedMap 의 자식객체
Collections의 sort()를 이용한 정렬
→ 객체가 Comparable을 구현하고 있는 경우 내장 알고리즘을 통해 정렬
사용자 정의 comparable 만들기
comparable
Person 클래스
package test07_Comparable;
public class Person {
private String name;
private String id;
public Person(String name, String id) {
this.name = name;
this.id = id;
}
}

⇒ sort 사용 불가
왜? comparable 인터페이스를 구현하고있지 않기 때문
package test07_Comparable;
public class Person implements Comparable<Person>{
private String name;
private String id;
public Person(String name, String id) {
this.name = name;
this.id = id;
}
@Override
public String toString() {
return "Person [name=" + name + ", id=" + id + "]";
}
@Override
public int compareTo(Person o) {
//이름순으로
return this.name.compareTo(o.name);
}
}
Comparable 인터페이스를 구현하도록 하고, compareTo 메서드를 재정의해주면? 사용이 가능해진다.

⇒ 위의 과정없이 정렬하는 방법 ? ⇒ Comparator 사용하기!
Comparator 인터페이스를 구현하는 새로운 Comparator 클래스를 만들어준다.
package test08_Comparator;
import java.util.Comparator;
public class AgeComparator implements Comparator<Person>{
@Override
public int compare(Person o1, Person o2) {
return Integer.parseInt(o2.getId()) - Integer.parseInt(o1.getId());
}
}
나와 다른거, comparable (파라미터 1개 필요)
comparator는 쟤랑 걔 비교( 파라미터2개 필요)

Hash 를 사용하는 이유?
⇒ hash 를 통해 내용물을 해쉬값으로 비교하고, 해쉬값이 같을 때만 equals( )를 체크하는 것이 그냥 모든값을 무조건 체크하는 것보다 더 효율적이다!!
참조자료형은 비교기준이 있어야만 정렬할 수 있는데 ,
String 자료형은 comparable의 구현체이다. (=비교기준이 있다)
String 은 char[] 문자 배열이다!
Comparable interface
→ 나 와 너 비교 = 파라미터가 한 개 필요
Comparator
→ 얘와 쟤 비교 = 파라미터가 두 개 필요.



